Observe, fit and simulate
MVEN10 Risk Assessment in Environment and Public Health
Exercise overview
We encourage collaboration
Reporting is individual
Background
Assessors often face the task to inform a model with available data.
The way data has been collected gives valuable information on how data is related to the quantity
Sample size, or rather the number of independent observations, should be large enough to establish a good fit.
Purpose
To find a suitable probability model (a probability distribution) for variability or measurement errors of a given random sample (repeated observations of he same thing), by
Estimating the model parameters using the information in the sample, and
Evaluate the goodness of fit of the model, and then
draw random numbers from the probability model (a probability distribution)
Content
Data sets collected by the students
Functions to fit a model to data and evaluate goodness of fit
Duration
60 minutes
Reporting
Write a report using a qmd document and upload it on the assignment in canvas. Instructions at the end of this page.
Choose data set
- Download the fill with all data sets and upload it in your project in the folder named data
Open the excel-file and see what it contains.
Load useful libraries for reading and plotting data
library(readxl)
library(dplyr)
library(ggplot2)- Read in data into a data frame named df and view it.
df <- read_excel(path="data/ex_obs_all.xlsx",sheet="data")
View(df)You are to use R to fit a probability distribution to the observations to two groups, one with discrete and one with continious observations.
Choose one of the columns to start with.
Decide if the data you have selected is continuous or discrete.
Below I refer to the column name for the chosen observations as obs. Note that I demonstrate the code on a different data set than yours.
This is my set of observations
df$obs [1] 145.9 2.4 0.5 28.3 13.7 27.8 17.8 18.1 3.8 24.1
[11] 290.6 14.6 22.6 219.3 0.6 31.6 10.5 4.3 3.3 1030.3- Make a histogram of data.
Change binwidth to modify the smoothness of the histogram.
ggplot(df,aes(x=obs))+
geom_histogram(binwidth = 60)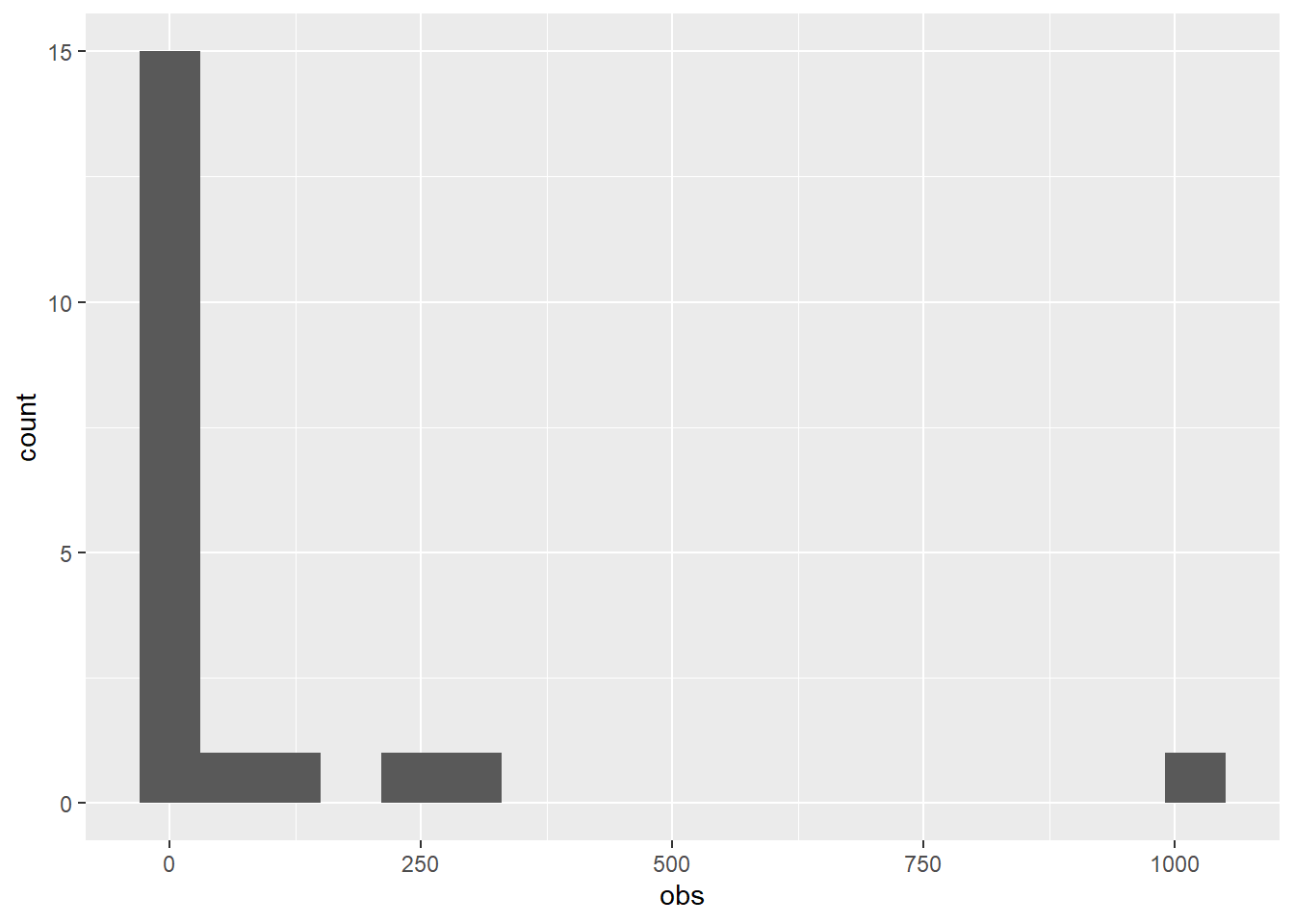
Find a suitable model for data
We will find a suitable model for data by fitting a probability distribution to data.
A distribution that fits well to data AND that seems reasonable for that quantity can be seen as a suitable model to describe variability for the quantity and/or measurement error for observations of the quantity.
- Install the R-package fitdistrplus.
Note that this only needs to be done one time and you can do it in the Console.
install.packages("fitdistrplus")- Load the R-package fitdistrplus and ignore warnings
library(fitdistrplus)Fit a model
We will find a model by fitting alternative reasonable probability distributions to data and then compare the fitted distributions.
We will use a normal, lognormal and an exponential distribution as candidate models for the continuous quantity.
- Fit a normal distribution to data using the function fitdist
Tip
Note that you can type a question mark in front of a function in the Console to view the help for the function
fitnorm = fitdist(df$obs, distr = "norm")
fitnormFitting of the distribution ' norm ' by maximum likelihood
Parameters:
estimate Std. Error
mean 95.5050 50.93555
sd 227.7928 36.01737- Study goodness of fit by comparing the histogram and fitted PDF and Empirical and theoretical CDFs. Note that if your plotting window is too small, then use zoom to enlarge it.
plot(fitnorm)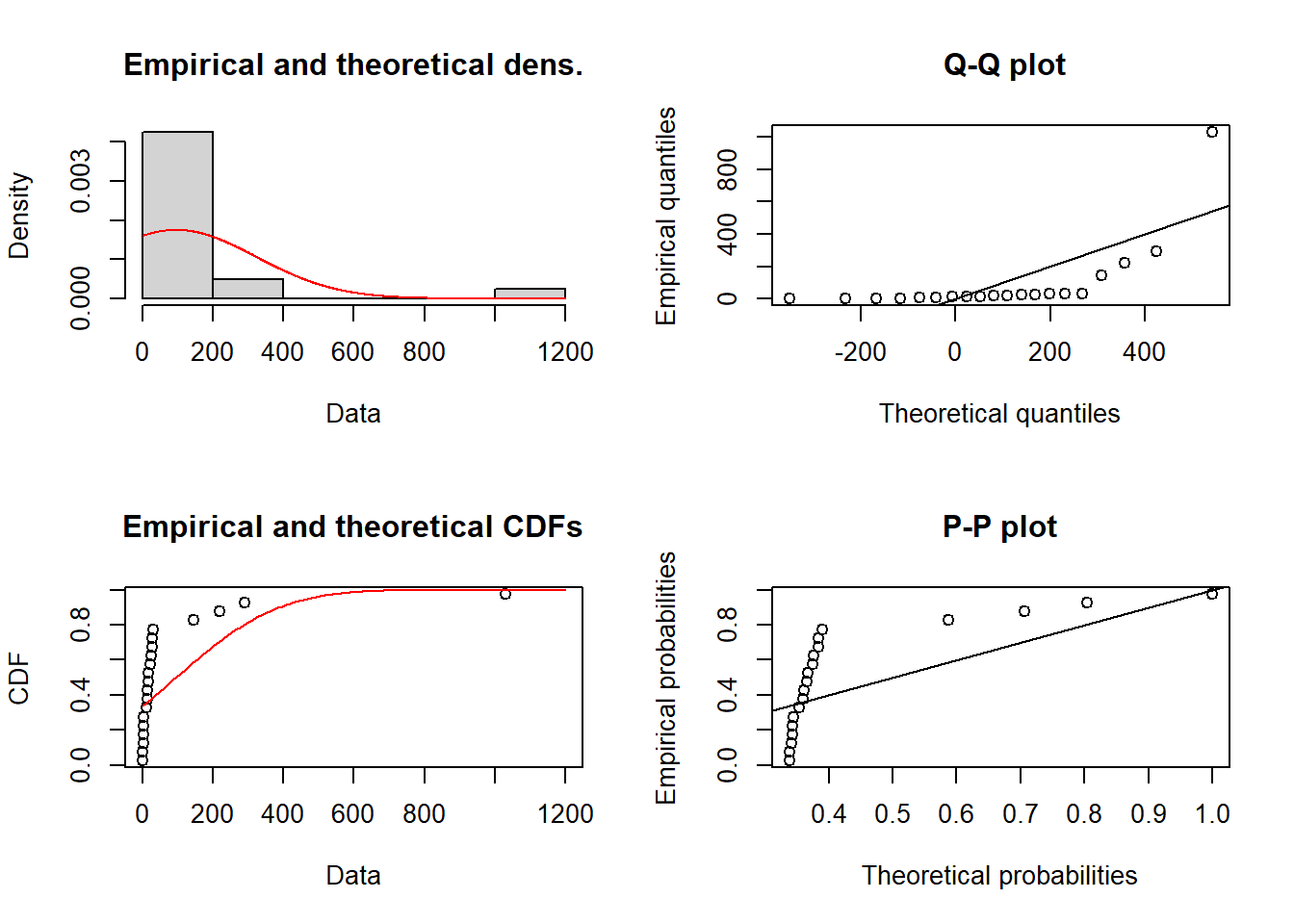
- Fit data to a lognormal distribution and view the PDF, CDF and quantiles
fitlnorm = fitdist(df$obs, distr = "lnorm")
fitlnormFitting of the distribution ' lnorm ' by maximum likelihood
Parameters:
estimate Std. Error
meanlog 2.824403 0.4234748
sdlog 1.893837 0.2994415plot(fitlnorm)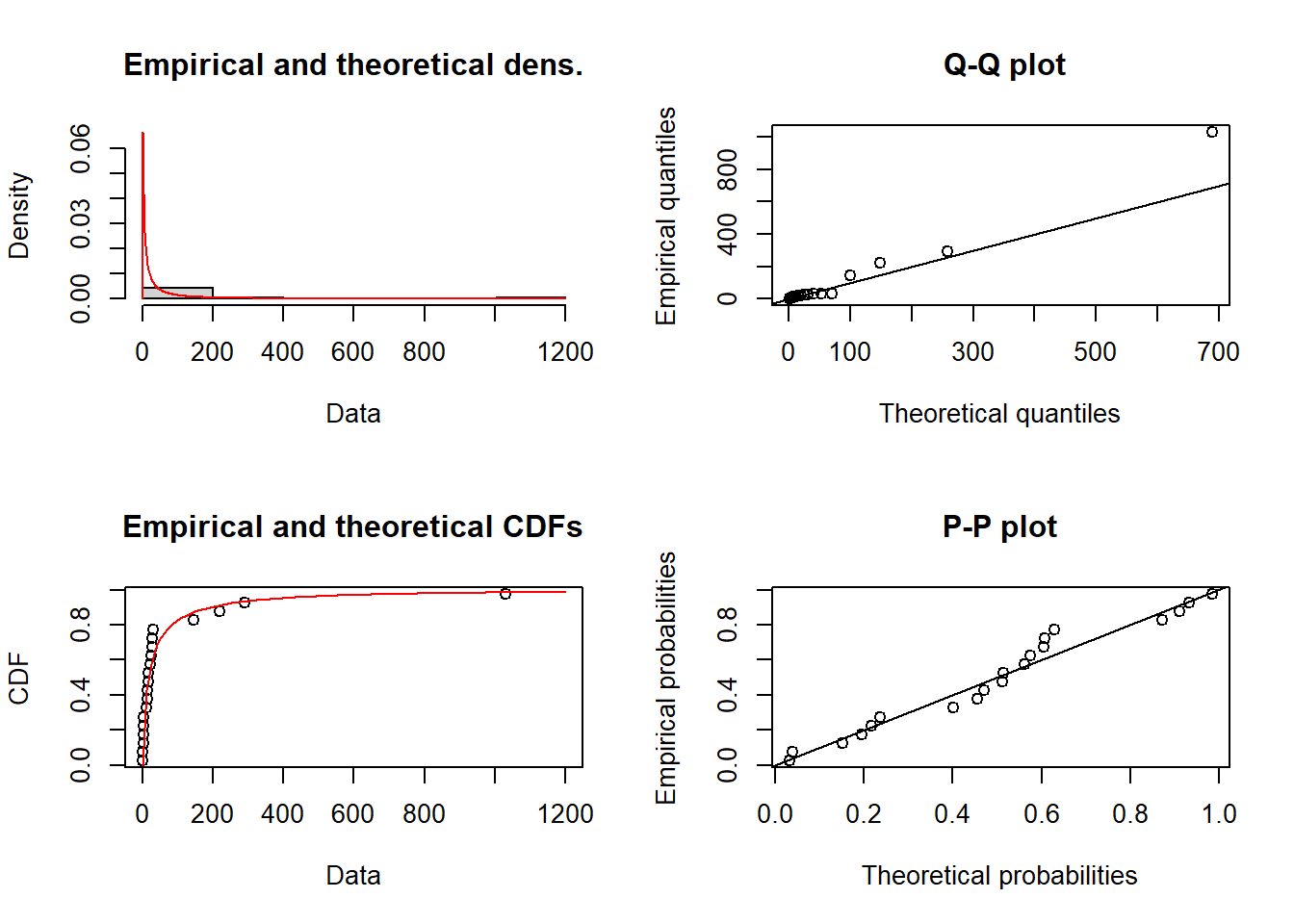
- Fit data to an exponential distribution and view the PDF, CDF and quantiles
fitexp = fitdist(df$obs, distr = "exp")
fitexpFitting of the distribution ' exp ' by maximum likelihood
Parameters:
estimate Std. Error
rate 0.01047066 0.002319722plot(fitexp)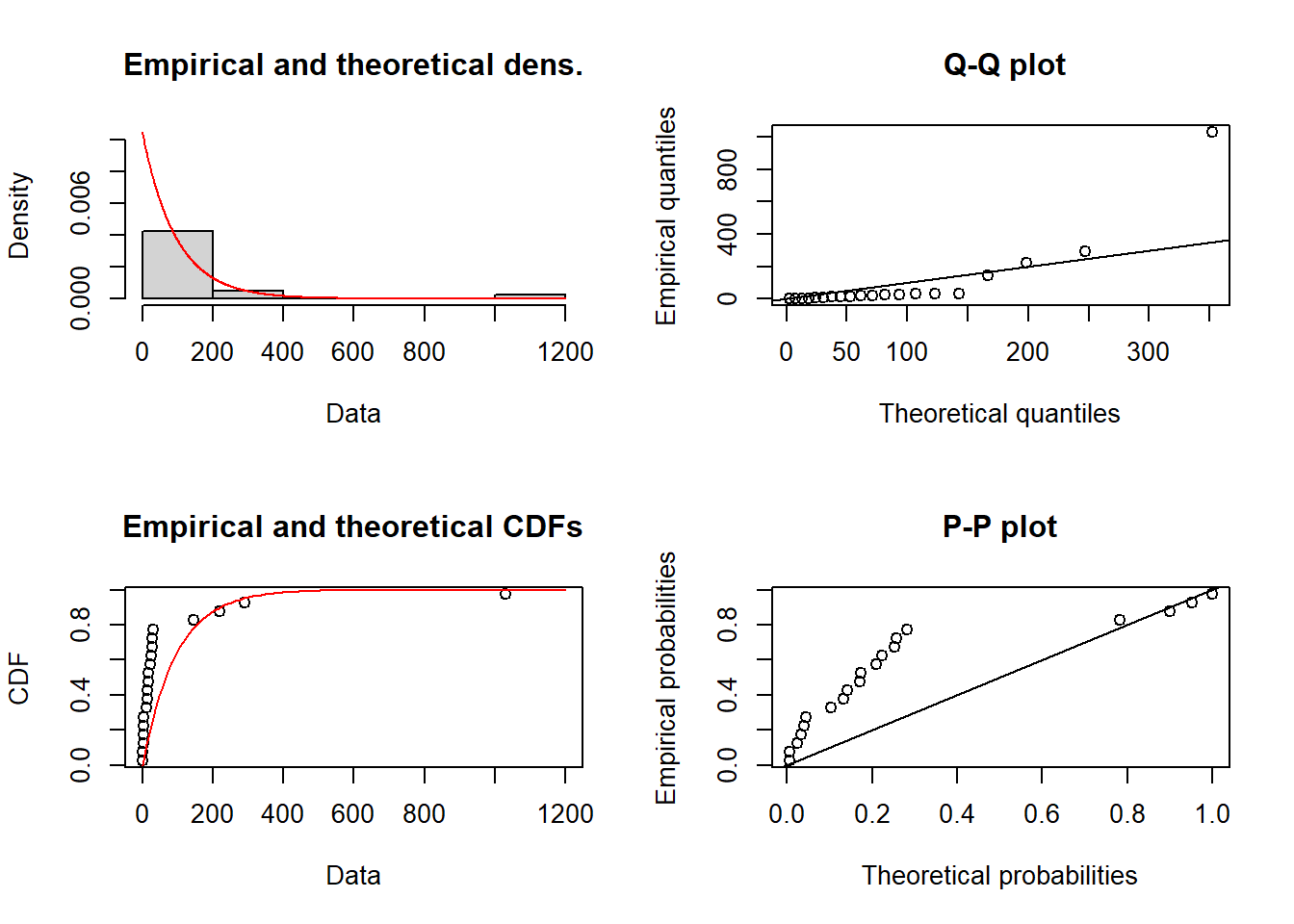
In addition to studying graphs, one can compare a measures of goodness-of-fit.
- Compare the goodness-of-fit measure AIC, where the lower AIC is the better.
fitnorm$aic[1] 277.895fitlnorm$aic[1] 199.2779fitexp$aic[1] 224.3671 [1] 0 4 0 2 2 3 1 2 1 1 0 5 0 0 3 2 2 2 2 4We will use negative binomial, binomial and poisson as candidate distributions for the discrete quantity.
- Fit a negative binomial distribution to data using the function fitdist
Tip
Note that you can type a question mark in front of a function in the Console to view the help
fitnbinom = fitdist(df$obs, distr = "nbinom", discrete=TRUE)
fitnbinomFitting of the distribution ' nbinom ' by maximum likelihood
Parameters:
estimate Std. Error
size 9.712325 22.6474743
mu 1.800161 0.3266524- Plot the fitted distribution and compare to data. Note that the plotting looks different from discrete data.
plot(fitnbinom)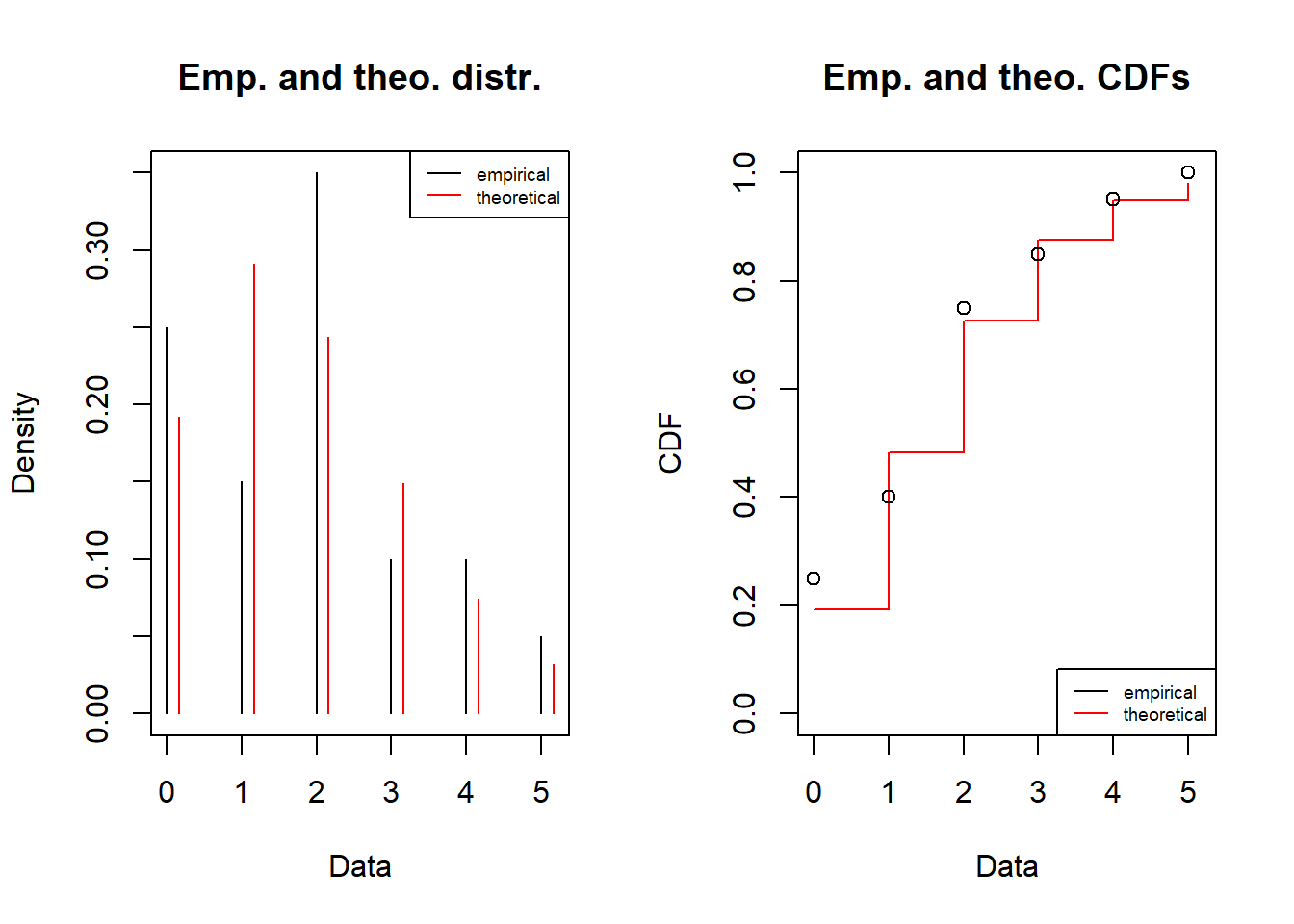
- Fit a binomial distribution to data
Note that in order to use the binomial you need to fix the number of trials and suggest a starting value for the probability to succeed in one trial.
In the code below, the binomial model is fitted using quantile matching estimation, and that is why we also provide two quantiles (probs) as input arguments to the function. The size parameter corresonds to the number of indpendent trials, and you can modify that to be smaller och larger integer.
fitbinom = fitdist(df$obs, distr = "binom", discrete=TRUE, start= list(size = 20, prob = mean(df$obs)/20), method = "qme", probs = c(0.25,0.75))
fitbinomFitting of the distribution ' binom ' by matching quantiles
Parameters:
estimate
size 20.00
prob 0.09plot(fitbinom)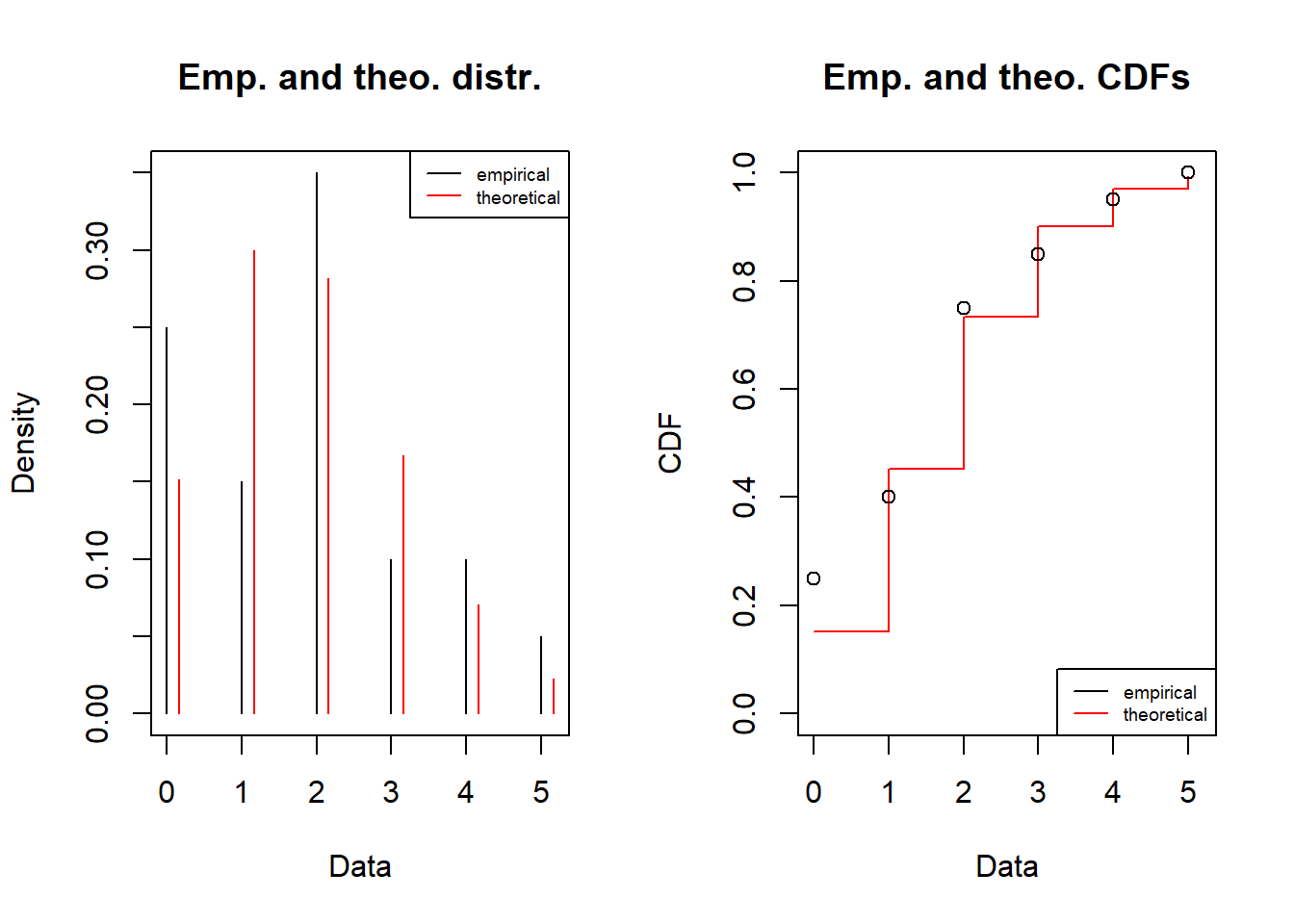
- Fit a poisson distribution to data
fitpois = fitdist(df$obs, distr = "pois", discrete=TRUE)
fitpoisFitting of the distribution ' pois ' by maximum likelihood
Parameters:
estimate Std. Error
lambda 1.8 0.2999999plot(fitpois)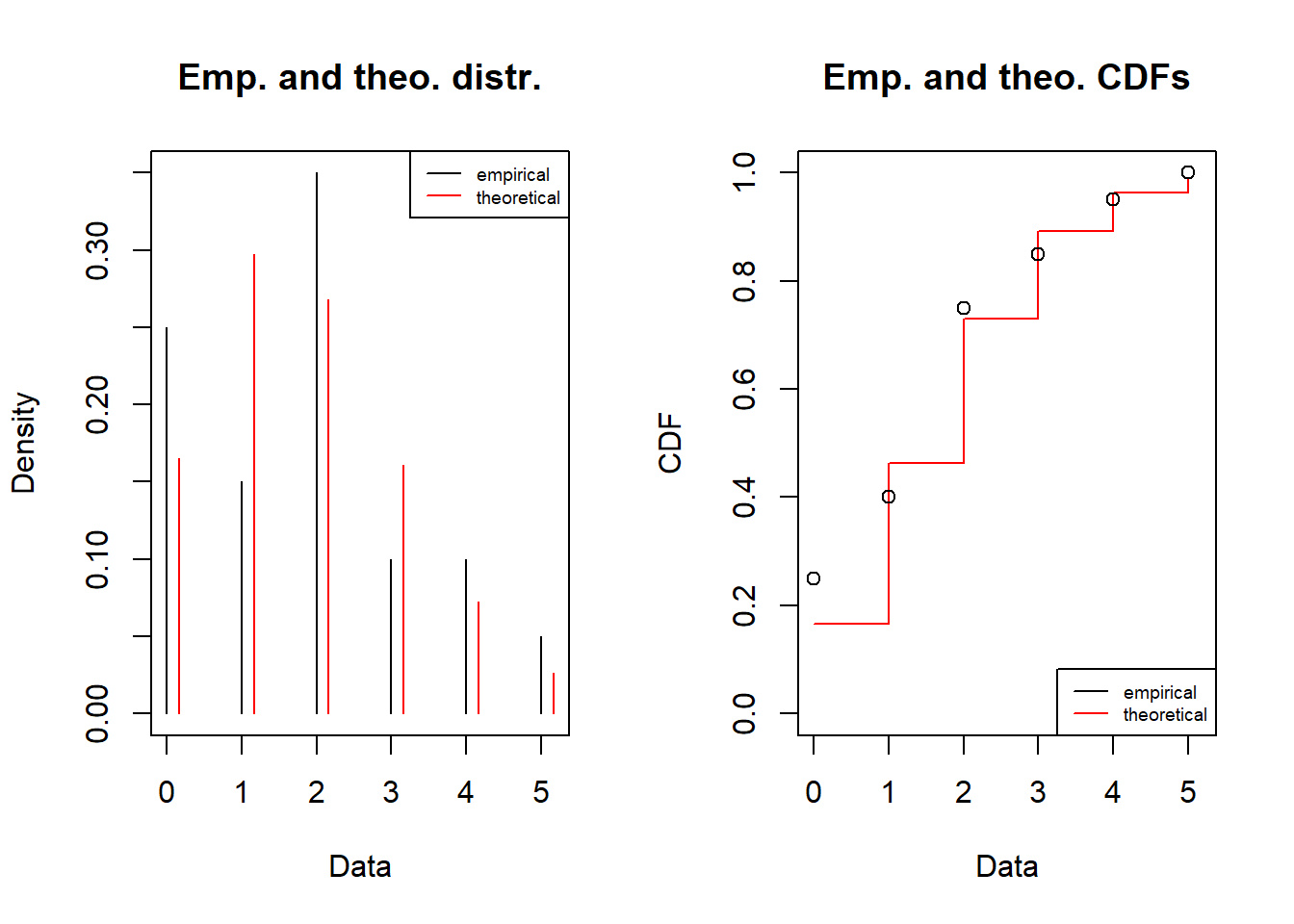
In addition to studying graphs, one can compare a measures of goodness-of-fit.
- Compare the goodness-of-fit measure AIC, where the lower AIC is the better.
fitnbinom$aic[1] 72.60253fitbinom$aic[1] 73.20188fitpois$aic[1] 70.83766- Choose the best model and justify your decision
Simulate
At this point you have a model for a quantity that is either a continuous or a discrete variable.
Now you are to simulate from the continuous model and visualise the results. Simulation is done by generating random numbers from the chosen probability distribution.
- Sample 10 000 random values from your choice of the best model.
Here is a code how to sample ten values from a fitted normal distribution.
- The parameters of the fitted distribution is found by typing $estimate after the fitted object. For a normal it is:
fitnorm$estimate mean sd
95.5050 227.7928 - use the function rnorm to sample niter = 10 values
niter = 10
rnorm(niter,fitnorm$estimate["mean"],fitnorm$estimate["sd"]) [1] -17.81796 395.94369 -196.89576 -372.27911 459.87993 123.21815
[7] -144.09099 -146.44296 -96.67299 334.91645- sample and plot as a histogram.
Here is a code how to do it for the normal distribution.
data.frame(x=rnorm(niter,fitnorm$estimate["mean"],fitnorm$estimate["sd"])) %>%
ggplot(aes(x=x)) +
geom_histogram()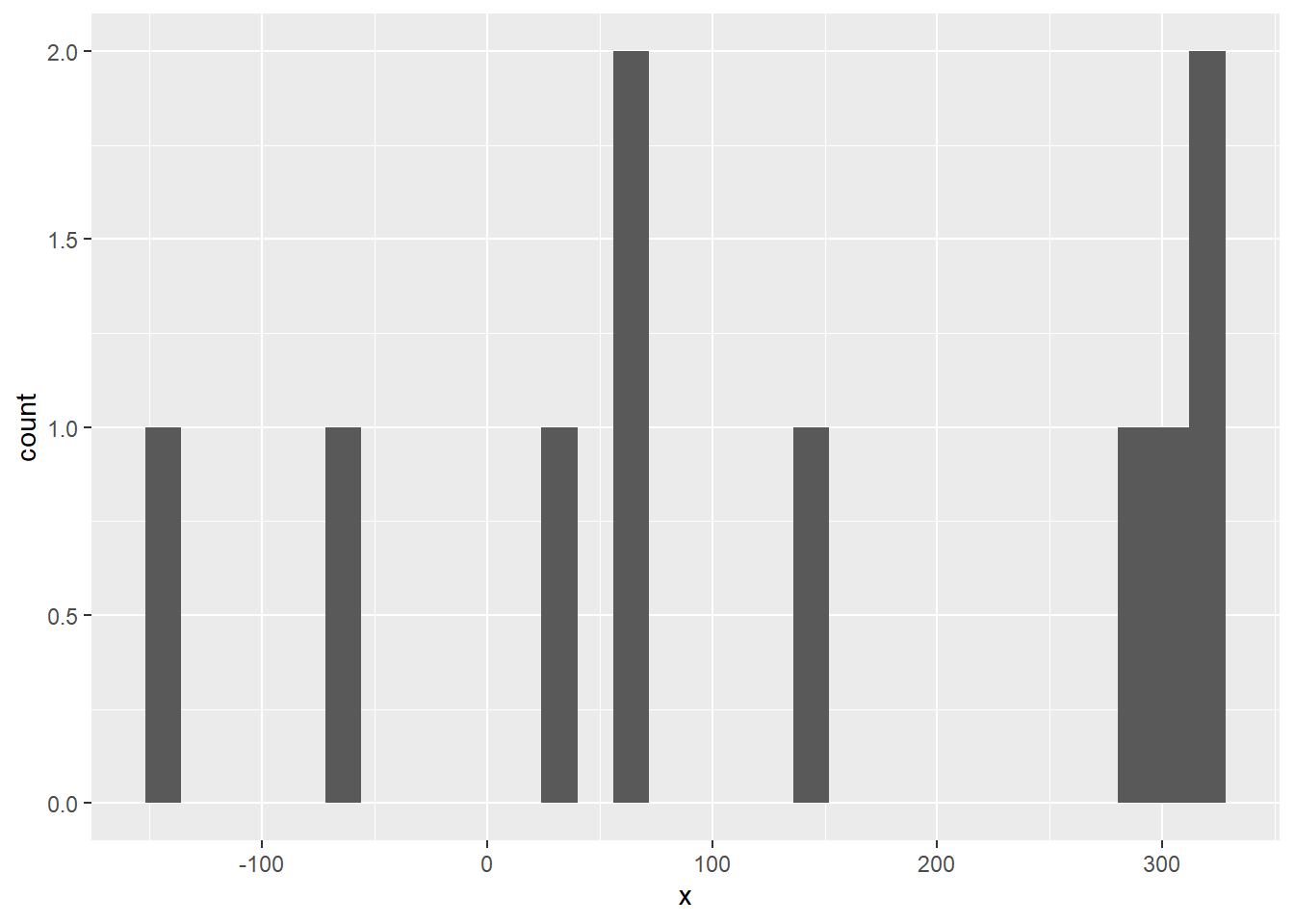
Report
Prepare a report including:
your name
your choice of the two data sets
your chosen models
include your justification
- refer to if the data is for a continuous or discrete quantity
- the goodness-of-fit measured by AIC in comparison to alternative models
- a graph comparing the histogram with the PDF of the fitted model and the empirical and theoretical CDFs
a histogram visualising a random sample of 10 000 values from the quantity
Use this template for the report